Hi there! I am Joy Yingqing He. 👋
I received my Ph.D. degree from HKUST in 2025, and was honored with a Best Research Award from HKUST in 2026.
My research journey started in 2021, supervised by Prof. Qifeng Chen and focused on Generative AI. My first project was about image generation and led to an Oral presentation at ACM MM within one month.
Then I continued to work on video and multimodal generation.
During two years (2022-2024) of working on 0-1 Video Pre-training and Video Foundational Architectures in Tencent AI Lab, I have published 10 papers in 2024, including 7 lead-authored (2 first-author (one of which is ICLR 2024 Spotlight) and 5 co-first-author) publications in top-tier AI conferences such as ICLR, Siggraph Asia, CVPR, ICCV, AAAI, etc.
These works provide systematic solutions for large-scale Video Generation, spanning Controllability, Multi-modality, and Foundational quality.
Prior to 2021, I was an MPhil student in the HKUST InnoX program (2019-2021), led by Prof. Zexiang Li, where I engaged in multidisciplinary exploration across various technological frontiers such as robotics and many others.
- [11/2025] 1 paper was accepted to AAAI 2026 as an Oral paper.
- [09/2025] 2 paper was accepted to ICCV 2025:
- [03/2025] 1 paper was accepted to CVPR 2025:
- [12/2024] 1 paper was accepted to AAAI 2025.
- [10/2024] 1 paper was accepted to WACV 2025.
- [08/2024] 1 paper was accepted to ECCV 2024 AI4VA Workshop.
- [07/2024] 1 paper was accepted to SIGGRAPH Asia 2024.
- [07/2024] 1 paper was accepted to ECCV 2024.
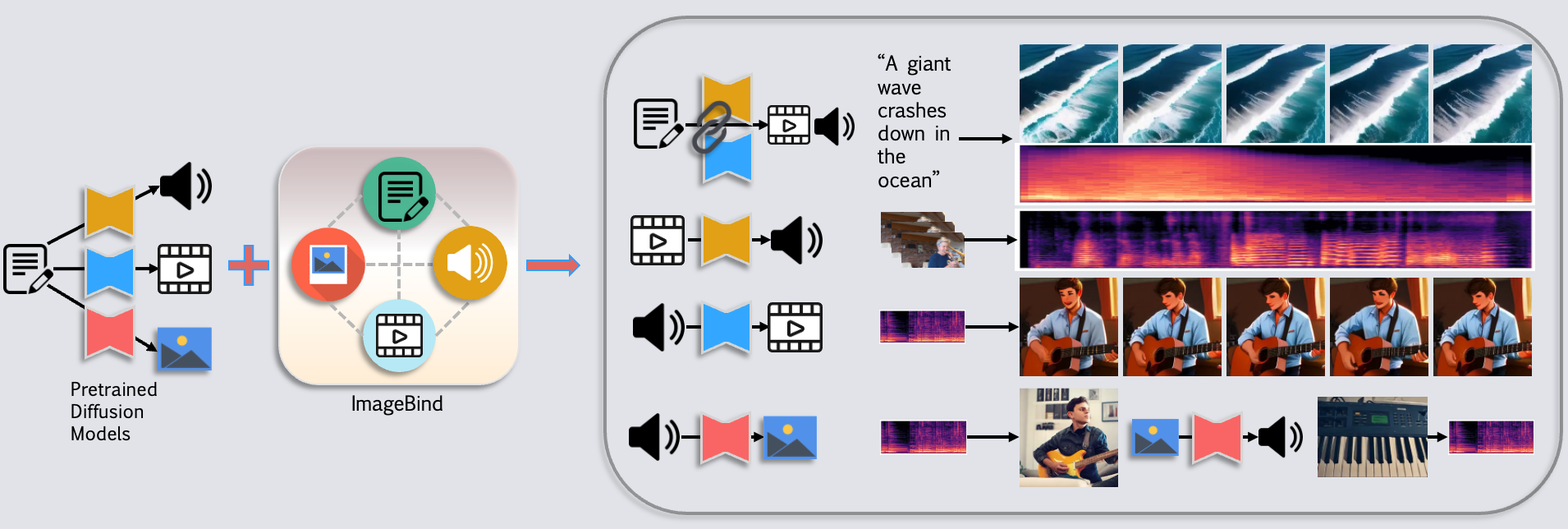
- [05/2024] We released a survey paper: LLMs Meet Multimodal Generation and Editing: A Survey.
- [03/2024] 1 paper was accepted to CVPR 2024.
- [02/2024] 1 paper was accepted to TVCG 2024.
- [01/2024] 2 papers were accepted to ICLR 2024 (including 1 Spotlight paper).
- [12/2023] 1 paper was accepted to AAAI 2024.
- [11/2023] We released VideoCrafter 1.
- [08/2023] 1 paper was accepted to SIGGRAPH Asia 2023.
- [04/2023] We released VideoCrafter 0.9.
- [08/2021] 1 paper was accepted to ACM MM 2021 as an Oral paper.
Talks
[12/2024] Invited talk, The 20th CSIG Conference on Young Scientists (CSIG 2024), Hangzhou, China.
VideoTuna is the first repo that integrates multiple AI video generation models for text-to-video, image-to-video, text-to-image generation for fine-tuning and post-training (to the best of our knowledge).
Additionally, VideoTuna provides a comprehensive pipeline in video generation, including pre-training, continuous training, post-training (alignment), and fine-tuning.
MMTrail is a large-scale multi-modality video-language dataset with over 20M trailer clips, featuring high-quality multimodal captions that integrate context, visual frames, and background music, aiming to enhance cross-modality studies and fine-grained multimodal-language model training.
This survey includes works of image, video, 3D, and audio generation and editing.
We emphasize the roles of LLMs on the generation and editing of these modalities.
We also includes works of multimodal agents and generative AI safety.
Given text description and video structure (depth), our approach can generate temporally coherent and high-fidelity videos. Its applications include dynamic 3d-scene-to-video creation, real-life scene to video, and video rerendering.
we propose an unsupervised method for portrait shadow removal, leveraging the facial priors from StyleGAN2.
Our approach also supports facial tattoo and watermark removal.
Internships
Tencent AI Lab | Research, Video Diffusion Models | 2022 – 2024